
티스토리 뷰
목차
728x90
오늘은 정렬 알고리즘을 들고 왔다!!
정렬 알고리즘에는 버블 정렬, 선택 정렬, 삽입 정렬, 퀵 정렬
이렇게 4가지의 종류가 있는데 각각 무엇을 나타내는지 따라 해 보자..!
● 정렬 알고리즘
- 버블 정렬
- 선택 정렬
- 삽입 정렬
- 퀵 정렬
# Swap Algorithm
a=10
b=5
# a=b
# b=a
# c=a
# a=b
# b=c
# print(a,b)
a,b = b,a
print(a,b)
5 10
1. 버블 정렬
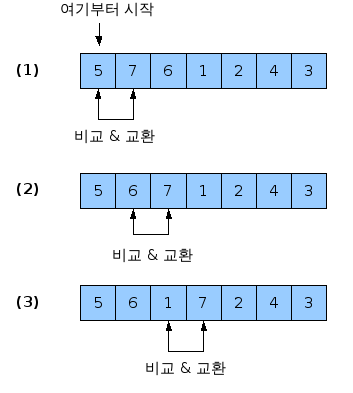
- 서로 이웃하는 것끼리 비교 후 교환
"""
55 7 78 12 42 n=5
----------------------
7_ 55_ 78 12 42
7 55_ 78 12 42
7 55 12 78- 42
7 55 12 42_ 78_
----------------------
7_ 55_ 12 42 78
7_ 12_ 55_ 42 78
7_ 12 42_ 55 78
----------------------
7_ 12_ 42 55 78
7_ 12_ 42 55 78
----------------------
7_ 12_ 42 55 78 반복 횟수 : n-1
"""
import time
def bubble_sort(arr):
start = time.time()
for i in range(0, len(arr)-1):
for j in range(0,len(arr)-1):
if arr[j]>arr[j+1]:
#자리바꿈
temp = arr[j]
arr[j] = arr[j+1]
arr[j+1] = temp
print("걸린시간 :", time.time()-start)
return arr
#-----------------------------------------
bubble_sort([55,7,78,12,42])
걸린시간 : 0.0
[7, 12, 42, 55, 78]import randomdata=random.sample(range(20),20)bubble_sort(data)
걸린시간 : 0.0
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]students = [
(1,"john",90,87,69),
(3,"tom",90,87,69),
(5,"jane",90,82,69),
(4,"marry",90,87,80),
(2,"dave",90,50,69)
]
students
[(1, 'john', 90, 87, 69),
(3, 'tom', 90, 87, 69),
(5, 'jane', 90, 82, 69),
(4, 'marry', 90, 87, 80),
(2, 'dave', 90, 50, 69)]bubble_sort(students)
걸린시간 : 0.0
[(1, 'john', 90, 87, 69),
(2, 'dave', 90, 50, 69),
(3, 'tom', 90, 87, 69),
(4, 'marry', 90, 87, 80),
(5, 'jane', 90, 82, 69)]start = time.time()
sorted(data)
print("걸린시간 :", time.time()-start)
# bubble_sort에 비해 sorted가 더 빠르다.
걸린시간 : 0.0
sorted("This is a test string from Python".split(), key=str.lower)
['a', 'from', 'is', 'Python', 'string', 'test', 'This']sorted(students, key=lambda stu:stu[0]) # 순번으로 정렬
# sorted(students, key=lambda stu:stu[1]) 이름으로 정렬
[(1, 'john', 90, 87, 69),
(2, 'dave', 90, 50, 69),
(3, 'tom', 90, 87, 69),
(4, 'marry', 90, 87, 80),
(5, 'jane', 90, 82, 69)]2. 선택 정렬

- 최대값 또는 최소값을 선택한 후 비교 교환
"""
55 7 78 12 42
-----------------------
7_ 55_ 78 12 42
7_ 55 78_ 12 42
7_ 55 78 12_ 42
7_ 55 78 12 42_
-----------------------
7 55_ 78_ 12 42
7 12_ 78 58_ 42
7 12_ 78 58 42_
-----------------------
7 12 58_ 78_ 42
7 12 42 78 58_
-----------------------
7 12 42 58_ 78_
"""
import time
def selection_sort(arr):
start = time.time()
for i in range(0, len(arr)-1):
#print("i가 " + str(i) + "일 때")
for j in range(i+1, len(arr)):
#print('j는 ' + str(j) + '번째와 비교,', end = ' ')
if arr[i] > arr[j]:
arr[i], arr[j] = arr[j], arr[i]
#print()
print("걸린 시간 : ", time.time() - start)
return arr
# -----------------------------------
selection_sort([55, 7, 78, 12, 42])
걸린 시간 : 0.0
[7, 12, 42, 55, 78]result = selection_sort(data)
걸린 시간 : 11.986129522323608
selection_sort(students)
걸린 시간 : 0.0010004043579101562
[(1, 'john', 90, 87, 69),
(2, 'dave', 90, 50, 69),
(3, 'tom', 90, 87, 69),
(4, 'marry', 90, 87, 80),
(5, 'jane', 90, 82, 69)]
{kind=link}
import time
def insertion_sort(arr):
start = time.time()
for i in range(0, len(arr)-1):
for j in range(i+1, len(arr)):
if arr[i] > arr[j]:
arr[i], arr[j] = arr[j], arr[i]
print("걸린 시간 : ", time.time() - start)
return arr
# -----------------------------------
insertion_sort([55, 7, 78, 12, 42])
걸린 시간 : 0.0
[7, 12, 42, 55, 78]"""
a = [2 4 5 1 3]
result = []
----------------
a = [4 5 1 3]
result = [2]
----------------
a = [5 1 3]
result = [2 4]
----------------
a = [1 3]
result = [2 4 5]
----------------
a = [3]
result = [1 2 4 5]
----------------
a = []
result = [1 2 3 4 5]
"""
'\na = [2 4 5 1 3]\nresult = []\n----------------\na = [4 5 1 3]\nresult = [2]\n----------------\na = [5 1 3]\nresult = [2 4]\n----------------\na = [1 3]\nresult = [2 4 5]\n----------------\na = [3]\nresult = [1 2 4 5]\n----------------\na = []\nresult = [1 2 3 4 5]\n'
def find_ins_idx(r, v):
for i in range(0, len(r)):
if v < r[i]:
return i
# 적절한 위치를 찾지 못했을 경우 v가 r의 모든 자료보다 크다는 뜻이므로 맨뒤에 삽입
return len(r)
def insertion_sort1(a):
result = []
while a:
value = a.pop(0)
ins_idx = find_ins_idx(result, value)
result.insert(ins_idx, value)
#print(a, result)
return result
# ---------------------
d = [2, 4, 5, 1, 3]
print(insertion_sort1(d))
[1, 2, 3, 4, 5]
import time
def insertion_sort2(arr):
start = time.time()
for i in range(0, len(arr)):
key = arr[i]
for j in range(i, 0, -1):
if arr[j-1] > key:
arr[j-1], arr[j] = arr[j], arr[j-1]
else:
break
print("걸린 시간 : ", time.time() - start)
return arr
# -----------------------------------
insertion_sort2([55, 7, 78, 12, 42])
걸린 시간 : 0.0
[7, 12, 42, 55, 78]start = time.time()
result = insertion_sort1(data)
print("걸린 시간 : ", time.time() - start)
걸린 시간 : 12.309948682785034
result = insertion_sort2(data)
걸린 시간 : 0.0
insertion_sort2(students)
걸린 시간 : 0.0
[(1, 'john', 90, 87, 69),
(2, 'dave', 90, 50, 69),
(3, 'tom', 90, 87, 69),
(4, 'marry', 90, 87, 80),
(5, 'jane', 90, 82, 69)]" 예시문제: 성적표 만들기 "
class Student():
def __init__(self, no, name, kor, eng, tot, avg, grade):
self.no = no
self.name = name
self.kor = kor
self.eng = eng
self.tot = tot
self.avg = avg
self.grade = grade
def print_info(self):
print("학번 : ", self.no)
print("이름 : ", self.name)
print("국어 : ", self.kor)
print("영어 : ", self.eng)
print("총점 : ", self.tot)
print("평균 : ", self.avg)
print("학점 : ", self.grade)
def insert_student():
no = input("학번 : ")
name = input("이름 : ")
kor = int(input("국어 : "))
eng = int(input("영어 : "))
print("학생 정보가 입력되었습니다.")
tot = kor + eng
avg = round(tot / 2, 3)
if avg >= 90:
grade = "A"
elif avg >= 80:
grade = "B"
elif avg >= 70:
grade = "C"
elif avg >= 60:
grade = "D"
else:
grade = "F"
student = Student(no, name, kor, eng, tot, avg, grade)
return student
def print_menu():
print("1. 데이터 추가")
print("2. 데이터 검색")
print("3. 데이터 삭제")
print("4. 데이터 정렬")
print("0. 종료")
menu = input("메뉴 선택 : ")
return int(menu)
# 검색
def search_student(name, slist):
flag = 0
for s in slist:
if s.name == name:
flag = 1
break
else:
flag = 0
if flag == 0:
print("==========================================================")
s.print_info()
print("==========================================================")
else:
print("해당 이름이 없다.")
# 삭제
def delete_student(name, slist):
for i, s in enumerate(slist):
if s.name == name:
del slist[i]
# main
print("********** 학생 관리 프로그램 ************")
student_list = []
while 1:
menu = print_menu()
if menu == 1:
student = insert_student()
student_list.append(student)
elif menu == 2:
name = input("검색할 이름을 입력 : ")
search_student(name, student_list)
elif menu == 3:
name = input("삭제할 이름을 입력 : ")
delete_student(name, student_list)
elif menu == 4:
sorted_list = sorted(student_list, key=lambda student:student.no)
for student in sorted_list:
student.print_info()
print("-----------------------")
else:
print("종료되었습니다.")
break
********** 학생 관리 프로그램 ************
1. 데이터 추가
2. 데이터 검색
3. 데이터 삭제
4. 데이터 정렬
0. 종료
메뉴 선택 : 1
학번 : 1
이름 : aaa
국어 : 97
영어 : 78
학생 정보가 입력되었습니다.
1. 데이터 추가
2. 데이터 검색
3. 데이터 삭제
4. 데이터 정렬
0. 종료
메뉴 선택 : 1
학번 : 2
이름 : bbb
국어 : 68
영어 : 72
학생 정보가 입력되었습니다.
1. 데이터 추가
2. 데이터 검색
3. 데이터 삭제
4. 데이터 정렬
0. 종료
메뉴 선택 : 2
검색할 이름을 입력 : bbb
해당 이름이 없다.
1. 데이터 추가
2. 데이터 검색
3. 데이터 삭제
4. 데이터 정렬
0. 종료
메뉴 선택 : 0
종료되었습니다.
user1 = student_list[0]
print(user1.no)
print(user1.name)
print(user1.kor)
print(user1.eng)
print(user1.tot)
print(user1.avg)
print(user1.grade)
user1.print_info()
1
aaa
97
78
175
87.5
B
학번 : 1
이름 : aaa
국어 : 97
영어 : 78
총점 : 175
평균 : 87.5
학점 : B
student_list
[<__main__.Student at 0x2782eb074f0>, <__main__.Student at 0x27824f0c670>]for student in student_list:
student.print_info()
print("-----------------------")
학번 : 1
이름 : aaa
국어 : 97
영어 : 78
총점 : 175
평균 : 87.5
학점 : B
-----------------------
학번 : 2
이름 : bbb
국어 : 68
영어 : 72
총점 : 140
평균 : 70.0
학점 : C
-----------------------
4. 퀵 소트
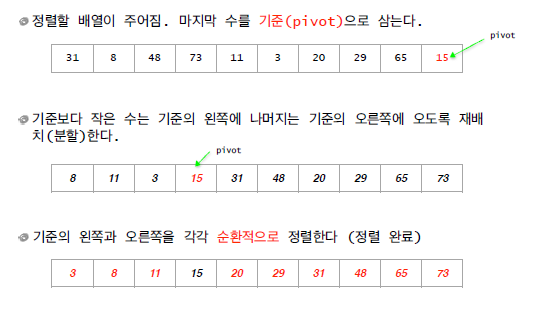
- 정렬 알고리즘의 꽃
- 기준점(pivot)을 정해서 기준점 보다 작은 데이터는 왼쪽, 큰 데이터는 오른쪽으로 모으는 함수를 작성
- 각 왼쪽, 오른쪽은 재귀 용법을 사용해서 다시 동일함수를 호출하여 위 작업을 반복
- 함수는 (왼쪽, 기준점, 오른쪽)을 리턴
- 0(n log n)
"""
3 9 4 7 0 1 5 8 6 2
----------------------------------------------
pivot = 0
0 9 4 7 3 1 5 8 6 2
pivot = 1
0 1 4 7 3 9 5 8 6 2
==============================================
3 9 4 7 5 0 1 6 8 2
-----------------------------------------------
pivot = 5
start = 3, end = 2
start = 9, end = 2 일 경우 교환
3 2 4 7 5 0 1 6 8 9
start = 4, end = 8
start = 7, end = 6 -> end = 1
3 2 4 1 5 0 7 6 8 9
start = 5, end = 0
3 2 4 1 0 5 7 6 8 9
"""
# 연습 1
data = [3,9,4,7,5,0,1,6,8,2]
left = list()
right = list()
pivot = data[0]
for idx in range(1,len(data)):
if data[idx] < pivot:
left.append(data[idx])
else:
right.append(data[idx])
print(left,pivot,right)
[0, 1, 2] 3 [9, 4, 7, 5, 6, 8]
import random
data = random.sample(range(100),10)
left = list()
right = list()
pivot = data[0]
for idx in range(1,len(data)):
if data[idx] < pivot:
left.append(data[idx])
else:
right.append(data[idx])
print(left,pivot,right)
[59, 34, 17, 44, 54, 1, 65] 84 [90, 85]
def quicksort(data):
if len(data)<=1:
return data
left,right = list(),list()
pivot = data[0]
for idx in range(1,len(data)):
if data[idx]<pivot:
left.append(data[idx])
else:
right.append(data[idx])
return quicksort(left) +[pivot] +quicksort(right)
data_list = random.sample(range(100),10)
quicksort(data_list)
[4, 23, 29, 39, 43, 51, 60, 79, 89, 98]students = [
(1,"john",90,87,69),
(3,"tom",90,87,69),
(5,"jane",90,82,69),
(4,"marry",90,87,80),
(2,"dave",90,50,69)
]
quicksort(students)
[(1, 'john', 90, 87, 69),
(2, 'dave', 90, 50, 69),
(3, 'tom', 90, 87, 69),
(4, 'marry', 90, 87, 80),
(5, 'jane', 90, 82, 69)]# pythonic
import random
def quicksort(data):
if len(data)<=1:
return data
left,right = list(),list()
pivot = data[0]
left = [data for data in data_list[1:] if data <= pivot ]
right = [data for data in data_list[1:] if data >= pivot ]
return quicksort(left) +[pivot] + quicksort(right)
data_list = random.sample(range(100),10)
quicksort(data_list)정렬 알고리즘도 알고리즘이라 그런지 어렵다...
각 알고리즘이 어떠한 형태를 가지고 있는지 이해는 되는 것 같다ㅎㅎㅎ
내가 주로 사용하는 부분은 아니지만 파이썬을 하는 입장에서
도움이 될 것 같기에..
매일매일 성장하는 나를 위해!! 가즈아~~

728x90
반응형
'Data Science' 카테고리의 다른 글
| [R] 비용 효율성 분석(Cost-effectiveness analysis)이란? (0) | 2022.06.20 |
|---|---|
| 칼만 필터(Kalman Filter)란? (0) | 2022.06.17 |
| 파이썬을 이용한 검색 알고리즘2(해시) (0) | 2022.06.09 |
| 파이썬을 이용한 검색 알고리즘(선형, 이진) (0) | 2022.06.08 |
| 파이썬을 이용한 알고리즘 (0) | 2022.06.07 |